[Review] BERT
Transformer 모델을 살펴보았으니, 이젠 본격적으로 BERT와 GPT을 살펴볼 차례이다. 이번에는 BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding[1] 논문을 읽고 리뷰해보자. 다음에는 GPT-1,2,3,4(4는 technical report인 게 아쉽지만)를 순서대로 리뷰해보는 시간을.
1. Introduction
BERT가 arxiv 기준 ver 1.이 2018년 10월 11일, GPT가 OpenAI 사이트 기준 2018년 6월 11일으로 나와있다. BERT 논문에서도 GPT와 어떤 점이 다른 지 여러 번 얘기하는 걸 보아 살짝 뒤늦게 나온 것이 맞는 것 같다. NLP 분야에서 Transformer가 나온 뒤에 이 구조를 응용하고자 하는 시도가 그 때 당시 확실히 많았던 것 같다. 확실히 transformer 모델이 커서 학습이 느린데다가, inductive bias가 CNN보다 작아 학습을 위해 dataset이 커야 되서 이것들이 단점으로 작용해 개선하고자 하는 노력이 있었던 것으로 보인다.
여하튼, NLP에서 task를 수행하는 데에 있어서 Feature-based approach와 fine-tuning approach 두 가지를 Related Work로 소개하고 있다. Feature-based unsupervised learning은 말 그대로 word-embedding, 더 나아가 paragraph-embedding, sentence-embedding representation을 학습하는 것으로, 실제 문장처럼 left-to-right representation 뿐만 아니라 right-to-left representation을 모두 학습한 ELMo가 당시 SOTA였다. Fine-tuning method는 잘 알려져있듯이, unlabeled text로부터 pre-trained된 contextual token representation encoder를 supervised downstream task의 initial parameter로 활용하여 fine-tuning 하는 것이다. Left-to-right LM과 auto-encoder objective로 pre-training한 GPT-1을 SOTA로 소개하고 있다.
그러나 ELMo와 GPT-1 모두 LTR, unidirectional LM이라 Transformer의 bidirectional, self-attention mechanism을 안 쓰고 있다. 이 특징이 pre-trained representation을 학습하는데 있어서 성능을 저해하는 문제점이기에, BERT는 이런 self-attention을 잘 활용하여 bidirectional model을 구성하였다. “GPT-1도 Transformer를 쓴다면서 self-attention이 있는거 아닌가?”하는 의문이 들 수도 있지만, GPT-1은 Transformer Decoder block의 Masked MHSA mechanism을 사용하는데, 이는 Transformer Review 때도 다루었지만 특정 시점 t에서의 output이 이전 시점 t-1, …에 의존하는, 그래서 LTR-LM 특징을 갖게 된다. GPT Review에서 자세히
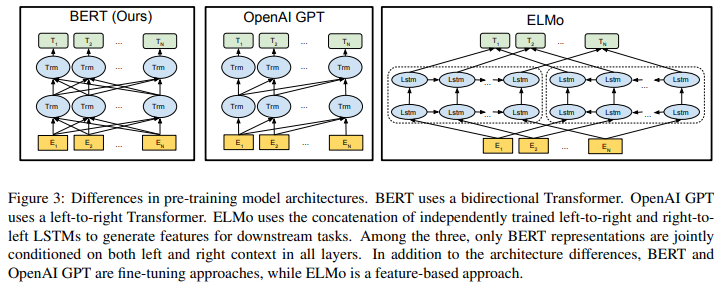
2. BERT
Architecture
BERT는 앞에 잠깐 말했듯이 Bidirectional Encoder Representations from Transformer의 약자로, 말 그대로 Transformer Encoder를 Bidirectional로 multi-layer 쌓은 구조이다. Encoder를 쌓아서 representation learning은 좋을 수 있으나, text generation에 대해서는 안 좋을 가능성이 있다는 점. 그래서 GPT가 텍스트 생성 분야에서 뛰어나서 인기가… BERT는 불쌍하다
Model Architecture의 parameter로 Transformer encoder block 개수 L, hidden feature size H, self-attention head 수 A 3개가 있다. BERT Base 모델은 L=12, H=768, A=12 (전체 parameter 수는 110M로, GPT-1과 비슷하게 하여 비교가 용이하도록 하였다), BERT Large 모델은 L=24, H=1024, A=16 (전체 parameter 수 340M)로 구성되어 있다.
Overall Process
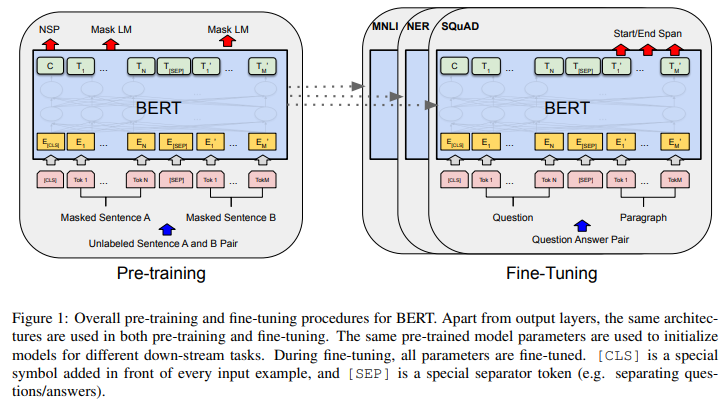
큰 틀은 앞서 말했던 Fine-tuning Approach이다. 그림처럼 Pre-training 이후 Fine-tuning으로 이어진다. 그림을 이해하기 위해선 우선 input이 어떤 식으로 tokenized 되는지 알아야된다.
BertTokenizer
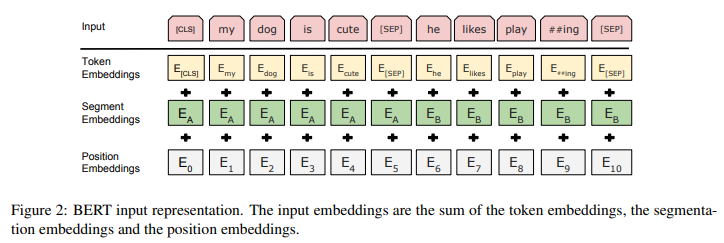
input으로 문장 1개 또는 문장 2개(Question&Answering pair 등)를 1개로 합친 걸 자유롭게 넣을 수 있다. 3가지 token의 합으로 input representation이 구성되는데, 첫 번째 Token Embedding은 “[CLS]”와 “[SEP]”라는 특수 토큰을 사용한다. CLS 토큰은 항상 문장의 맨 앞에 삽입되어, classification task에서 사용된다. (이외의 task에서는 무시) SEP 토큰은 문장 2개를 구분하는 토큰으로, 문장 끝에 SEP 토큰이 붙는다. 두 번째 Segment Embedding은 해당 토큰이 첫 번째 문장인지, 두 번째 문장인지 나타낸다. 마지막 Position Embedding은 기존 Transformer에서도 있던 typcial한 위치 임베딩이다. BERT는 WordPiece embedding을 사용하였다고 적혀있는데, 3만개의 token vocabulary에 없으면 “[UNK]” 토큰이 들어간다. implementation은 아래 HuggingFace에서 제공하는 BertTokenizer의 parameter를 보면 이해가 되더라.
Pre-training
BERT는 2개의 unsupervised tasks로 pre-training을 진행한다.
Maksed LM(MLM)
논문에서 강조하는 내용이 “Bidirectional”인데, 이를 구현하기 위한 task이다. 저자는 단순히 bidirectional로 학습 시 각 단어가 자기 자신을 보는 방식으로 단순한 학습이 될 가능성이 있다고 판단하여, 15%를 masking하고 이 masked token을 예측하는 task를 채택하였다. 그리고 “[MASK]” 토큰은 fine-tuning 시에는 없기 때문에, 이런 mismatch를 해결하기 위해 항상 masked work에 [MASK] 토큰을 씌우지 않고, 80%는 씌우고, 10%는 random token으로 바꾸고, 나머지 10%의 확률로 아예 바꾸지 않는 방식을 채택했다. masked token 위치에 있는 output을 softmax 해서 vocabulary 전체에 대해 CrossEntropyloss로 학습했다.
Next Sentence Prediction(NSP)
Question-Answering Task나 Natural Langauge Inference Task는 특히나 두 문장간의 연관성이 중요하기에, NSP task도 학습 과정에 포함한다. Pre-training data에서 50%는 진짜 다음 문장을 (label:IsNext), 50%는 그냥 아무 문장(label:NotNext)을 주어서 이를 파악한다. 이 때, 위의 overall process 그림에서 나와있듯이 [CLS] 토큰을 이용한다. label이 있으니까.
Fine-tuning
Fine-tuning은 논문에도 나와있듯이 straightforward하다. Paraphrasing Task 시 문장 pair를, Entailment Task 시 Hypothesis-Premise pair를, Question Answering Task 시 Question-Passage pair를, Text Classification/Sequence Tagging Task 시 degenerate text-$\phi$ pair를 주면 되겠다. 그리고 추가로 classification layer 등 task에 맞게 layer 몇 개를 output 이후에 추가해주어서 학습하면 되겠다. 예를 들어, SQuAD는 한 구절에서 질문에 대한 Answer를 예측하는 Task라서 위의 overall process 그림에서 처럼 두 번째 문장을 output으로 활용하면 되겠다.
Ablation Study
- Pre-training Task 2개의 effect에 대해 알아보기 위해, 기존 BERT Base 모델에서 NSP 없이 MLM만으로 학습한 모델, NSP 없이 MLM이 아닌 LTR로 학습한 모델의 성능을 비교하고 있다. 결과는 예상하다싶이, NSP를 없애면 성능 저하가 있고, 마찬가지로 MLM이 아닌 LTR model을 사용하면 성능 저하가 있다.
- Model Size는 크면 클 수록 pre-training의 장점을 극대화 할 수 있다고 말하고 있다. BERT Large 모델로 제시한 것 보다 더 큰 parameter로 해본 게 없는 게 좀 걸리긴 한다.
- Fine-tuning approach가 아닌 Feature-based approach로 하기 위해 BERT의 fine-tuning 없이 마지막 몇 개 layer의 activation을 없애고 2-layer 768-dim. BiLSTM layer를 classification layer 이전에 추가해주었을 때의 결과를 주었다. 그랬을 때 top 4 hidden layer concatenation의 결과가 가장 우수했으며, BERT Base 모델과 0.3 F1 score (CoNLL-2003 Named Entity Recognition)밖에 뒤쳐지지 않아서 별 차이가 없다. 마찬가지로 BERT가 효과적이다고 말하고 있다.
3. Experiments
GLUE Benchmark
GLUE(General Language Understanding Evaluation) Benchmark는 자연어 처리 모델의 성능을 보기 위해 다양한 dataset에서 다양한 task를 모두 수행해 이를 종합한 성능을 평가하는 벤치마크로, 여러 NLP 논문에 자주 보인다. BERT에서도 “GLUE에서 SOTA를 달성했다”는 문장이 있으니, 이 참에 알아보고 넘어가자.
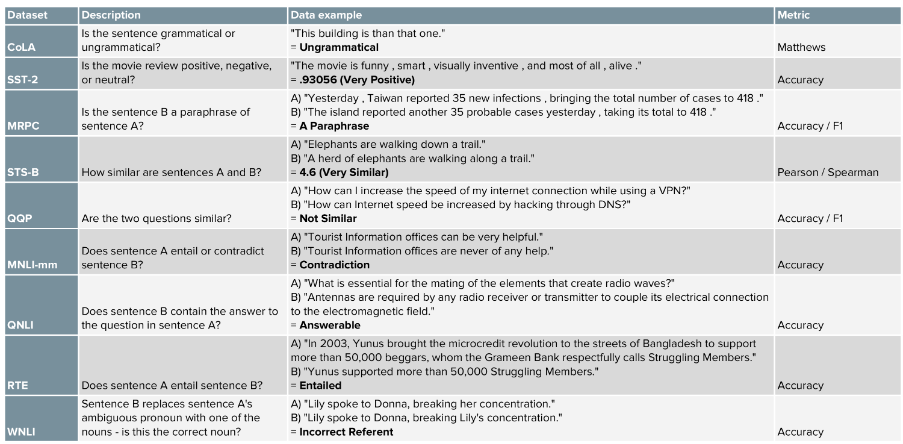
- CoLa Dataset: 문장의 문법이 맞는가?
- SST-2 Dataset: 영화 review가 긍정적인가?부정적인가?(혹은 중립적인가?)
- MRPC Dataset: 문장 pair가 의미론적으로 동일한가?
- STS-B Dataset: 문장 pair가 얼마나 유사한가? (1~5 범위)
- QQP Dataset: 질문 pair가 얼마나 유사한가?
- MNLI-mm Dataset: 문장 A가 문장 B와 모순적(mismatch)인가?
- MNLI-m Dataset: 문장 A가 문장 B와 일치(match)하는가?
- QNLI Dataset: 문장 B가 질문 A의 답을 포함하고 있는가?
- RTE Dataset: 문장 A가 문장 B를 포함하는가? (MNLI-m과 동일한 Task)
- WNLI Dataset: 문장 A에 있는 pronoun을 진짜 명사로 바꾼 문장 B가 올바른가?
- AX Dataset: Natural Language Inference (NLI) problem. GLUE 논문에서 “The set is provided not as a benchmark, but as an analysis tool for error analysis, qualitative model comparison, and development of adversarial examples.”라고 되있어서 벤치마크는 아니다.
그렇다면 2023년 6월 28일 기준 top은 무엇일까? gluebenchmark leaderboard를 살펴보자.
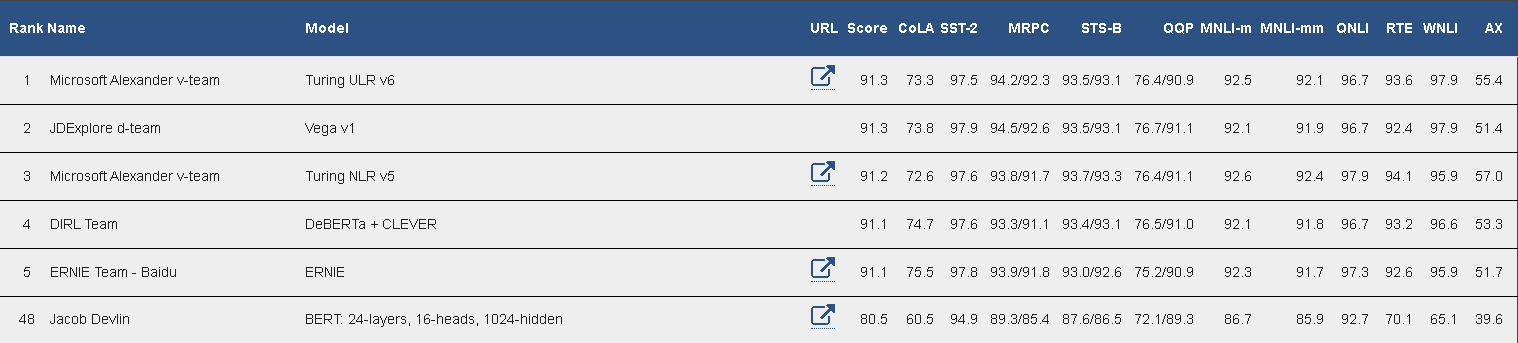 논문에 있는 BERT large 모델은 현재 48등이고, 놀라운 점은 1등도 “XY-LENT: X-Y bitext enhanced Language ENcodings using Transformers”, 결국 Transformer 구조라는 것과 전체적으로 BERT의 variant들이 매우매우 많다는 점. 논문에서는 WNLI set이 당시에 뭐 문제가 있었는지 그 결과를 제외하고 전체 결과를 주고 있다.
논문에 있는 BERT large 모델은 현재 48등이고, 놀라운 점은 1등도 “XY-LENT: X-Y bitext enhanced Language ENcodings using Transformers”, 결국 Transformer 구조라는 것과 전체적으로 BERT의 variant들이 매우매우 많다는 점. 논문에서는 WNLI set이 당시에 뭐 문제가 있었는지 그 결과를 제외하고 전체 결과를 주고 있다.
이 외에도 SQuAD (Standford Question Answering Dataset, task: to predict the answer text span in the passage), SWAG (Situations With Adversarial Generations, task: to choose the most plausible continuation among 4 choices) 등에서 SOTA를 기록했다. 그 때 당시
Reference
Websites
[사이트 출처 1] (https://huffon.github.io/2019/11/16/glue/)
[사이트 출처 2] (https://gluebenchmark.com/leaderboard/)
Papers
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
댓글남기기