[DCASE Task 2] 22W 개별연구 내용 정리
DCASE2020 Task2 설명
DCASE 2020 Challenge Task 2 “Unsupervised Detection of Anomalous Sounds for Machine Condition Monitoring”는 ToyCar, ToyConveyor (ToyADMOS Dataset의 일부), fan, pump, slider, and valve (MIMII Dataset의 일부) 총 6개의 machine에 대해 주어진 sound data가 정상인지(normal) 비정상인지(anomaly) 구분하는 Task이다.
각 machine에 대해 종류(id)는 총 7개로 (ToyConveyor만 id가 6개) 구성되어 있다. 모델을 구성하여 Test data에 대한 Anomaly score를 계산하고, AUC와 pAUC(p=0.1)를 통해 모델을 평가한다. (Sound data 수집 방법 및 사용 가능한 External Dataset에 대한 자세한 설명은 상단 링크에서)
내가 생각하기에 특이 사항으로는,
- Training data가 오직 normal data로만 이루어져있다는 점. (물론 이 점도 의심해봐야된다. Data labelling이 100% 정확한지 의문을 가질 수 있기에…)
- Development Dataset에서의 AUC, pAUC 또한 Result로 제공해주고 있다는 점. 해당 결과가 평가에 들어갔는지는 잘 모르겠지만, 해당 data는 validaion set으로 활용하는, labeled data인데 의미가 있는지 모르겠다. Evaluation Dataset으로 제공된 unlabeled data만의 결과가 중요한건데..
- ToyConveyor가 가장 말썽이다. ID 간 특성이 매우 뚜렷하여, 통합된 하나의 모델을 사용하기에 뭔가 구분이 힘들다.
이미 종료된 Task 이기에, Evaluation Dataset (Test set)에 label이 공개되었다.
Ground Truth for DCASE 2020 Challenge Task 2 Evaluation Dataset
My Best Result
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 95.57 | 89.20 | Eval | ToyCar | 93.50 | 89.33 |
| ToyConveyor | 76.11 | 66.90 | ToyConveyor | 85.95 | 71.37 | ||
| Fan | 87.65 | 81.78 | Fan | 94.87 | 91.58 | ||
| Pump | 91.96 | 82.77 | Pump | 94.71 | 86.72 | ||
| Slider | 98.54 | 93.12 | Slider | 96.51 | 87.68 | ||
| Valve | 99.50 | 98.35 | Valve | 98.66 | 96.67 | ||
| Mean | 91.55 | 85.35 | Mean | 94.03 | 87.22 | ||
| Harmonic Mean | 90.79 | 84.06 | Harmonic Mean | 93.86 | 86.45 |
1. Classification-based Method
Basic idea
Classification 기반의 방법으로는, 각 machine 별 id가 총 7개 (ToyConveyor는 6개)인데 이를 구별하는 model을 만드는 방법이 있다. 이 때, Anomaly Data는 Normal Data에 비해서 특정 id로 구분될 확률이 낮기 때문에, Classification model의, softmax를 거친 결과값이 작게 나올 것이라 예상할 수 있다.
Model Architecture
2020년 당시 결과를 제출한 팀들의 Technical Report를 보면, 이 방법을 이용한 팀들은 Mobilenetv2를 주로 사용했는데, 이유는 잘 모르겠다. Densenet이 2017년에 나오고, Mobilenet이 2018년에 나오고, Efficientnet이 2019년에 나왔는데 그 때 당시 가장 최근 model architecture도 아니고..
여하튼 나는 ResNet50을 사용했다. (ResNet101은 성능이 더 안 좋았다.) torchvision resnet source code를 참고하였고, Margin-based loss (ArcFace, CosFace 등)를 사용할 때는 Bottleneck structure를 사용하지 않고 ArcFace 논문[1]에서 사용한, BN-Conv-BN-PReLU-Conv-BN unit과, feature extraction으로 global pooling 대신 BN-Dropout-FC-BN을 채택하였다. 그렇지 않을 때는 (original cross-entropy loss) bottleneck structure를 그대로 사용하였다.
Hyperparameter setting & etc.
우선, 이 task에서 모델의 input으로 raw data를 넣어도 되지만, 거의 모든 팀들이 mel-spectrogram를 이용하였다. torchaudio Melspectrogram 물론 나도 ^.^
Signal Processing을 위한 hyperparameter로는, sampling rate는 16kHz, window size는 1024, hop-size는 512, mel-filterbank #는 128(typical). [2] Batch size는 64, Optimizer는 weight_decay 없는 Adam, scheduler는 커스터 마이징하여 사용하였다.
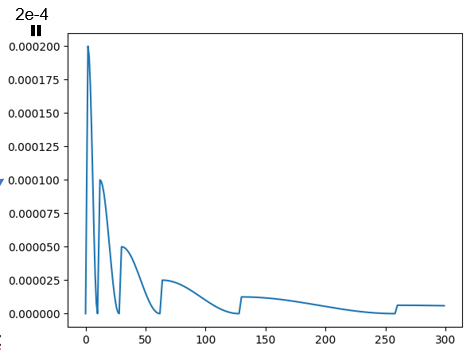
Max_lr=2e-4, T_up=2, T_0=10, T_mult=2로 했는데 이게 내 의도와 얼추 맞기는 하지만 정확히 원하는 대로 되지는 않고 있다. 코드를 좀 뜯어봐야 될 것 같다.
모델 학습 시 2 epoch 마다 Validation set에서 AUC, pAUC를 계산하고 최대가 될 때가 가장 좋은 모델이기에 그 모델의 파라미터 값을 저장하는 방식을 채택했다.
One integrated-Model vs One model per machine
2022W 개별연구 주제로 사수 선배님께서 던져주신 Task이다! ID-classification model을 구성하는 방법은 두 가지를 떠올려볼 수 있다.
- 1. 6개의 machine 각각에 대해 id 7개 (ToyConveyor만 6개)를 구분하는 model을 만들기
- 2. machine 구별 않고 id 총 41개를 구별하는 통합 model 하나를 만들기
1번의 경우 2 epoch 마다 AUC, pAUC 총 12개의 값의 총 합이 최대가 될 때 모델을 갱신하도록 하였다. Mix-up, label-smoothing=0.05, ArcFace Loss (아래 Several Techniques 부분 참조) 를 사용하였을 때 두 가지 방법의 결과는 다음과 같다.
Six Individual-Models
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 94.62 | 87.77 | Eval | ToyCar | 89.85 | 87.05 |
| ToyConveyor | 79.21 | 68.52 | ToyConveyor | 78.39 | 64.12 | ||
| Fan | 84.83 | 77.42 | Fan | 90.96 | 88.63 | ||
| Pump | 87.83 | 78.82 | Pump | 91.55 | 81.79 | ||
| Slider | 94.33 | 78.19 | Slider | 87.56 | 71.70 | ||
| Valve | 94.96 | 90.50 | Valve | 97.51 | 94.65 | ||
| Mean | 89.30 | 80.20 | Mean | 89.30 | 81.32 | ||
| Harmonic Mean | 88.89 | 79.54 | Harmonic Mean | 88.92 | 79.89 |
One Integrated-Model
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 94.84 | 88.82 | Eval | ToyCar | 96.16 | 91.69 |
| ToyConveyor | 80.09 | 66.91 | ToyConveyor | 83.81 | 69.59 | ||
| Fan | 84.92 | 77.22 | Fan | 96.57 | 90.54 | ||
| Pump | 89.68 | 80.88 | Pump | 93.72 | 85.10 | ||
| Slider | 97.92 | 89.34 | Slider | 91.50 | 79.35 | ||
| Valve | 97.01 | 94.49 | Valve | 99.10 | 97.47 | ||
| Mean | 90.75 | 82.85 | Mean | 93.48 | 85.62 | ||
| Harmonic Mean | 90.26 | 81.78 | Harmonic Mean | 93.20 | 84.58 |
통합된 한개의 모델을 쓸 때 4%p 정도 더 좋은 성능을 보이고 있다. Validation set에서의 1%p 정도 차이보다 더 큰 차이를 Test set에서 보이고 있다. 이는 Feature extraction 과정에서의 kinda overfitting으로 예상했는데, 어느정도 맞는 것 같다! 자세한 내용은 아래 Transfer Learning 부분 참조.
Several Techniques
Mix-up
Data-augmentation으로 mix-up을 사용했다. 주로 쓰는 것과 같이 Beta(1,1)을 따르도록 했다.
Label-smoothing
Multi-class classification에서 빠질 수 없는 CrossEntropy Loss. 여기서 label-smoothing 값을 주어 성능 개선을 조금이나마 기대했다. 결과는 아래와 같다. (One-integrated model)
Label-smoothing=0.0
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 93.01 | 88.09 | Eval | ToyCar | 92.66 | 89.34 |
| ToyConveyor | 75.64 | 64.61 | ToyConveyor | 75.03 | 63.31 | ||
| Fan | 83.58 | 75.52 | Fan | 96.47 | 89.91 | ||
| Pump | 89.07 | 80.29 | Pump | 93.16 | 84.12 | ||
| Slider | 95.20 | 84.55 | Slider | 89.92 | 76.57 | ||
| Valve | 95.58 | 92.03 | Valve | 98.91 | 96.74 | ||
| Mean | 88.68 | 80.85 | Mean | 91.03 | 83.33 | ||
| Harmonic Mean | 88.06 | 79.77 | Harmonic Mean | 90.29 | 81.75 |
Label-smoothing=0.05(위 Integrated-Model와 같은 값)
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 94.84 | 88.82 | Eval | ToyCar | 96.16 | 91.69 |
| ToyConveyor | 80.09 | 66.91 | ToyConveyor | 83.81 | 69.59 | ||
| Fan | 84.92 | 77.22 | Fan | 96.57 | 90.54 | ||
| Pump | 89.68 | 80.88 | Pump | 93.72 | 85.10 | ||
| Slider | 97.92 | 89.34 | Slider | 91.50 | 79.35 | ||
| Valve | 97.01 | 94.49 | Valve | 99.10 | 97.47 | ||
| Mean | 90.75 | 82.85 | Mean | 93.48 | 85.62 | ||
| Harmonic Mean | 90.26 | 81.78 | Harmonic Mean | 93.20 | 84.58 |
Label-smoothing tech.를 적용한 것이 적용하지 않은 모델에 비해 2%p 정도 성능이 좋았다. 그리고 label smoothing 값이 너무 크면 또 안 되기에, 0.1과 거의 성능이 흡사한 0.05를 채택!
Margin-based Loss
CrossEntropy Loss 말고 ArcFace(Adding Angular Margin)나 CosFace(Adding Cosine Margin)와 같은 margin-based Loss를 사용했다. 당연히 결과가 좋았는데, 아래와 같다.
(scale=30, margin=0.05 값을 사용하였다. margin=0.05는 2048-dim에서 매우 작아서 의미 없을 거라 생각했는데, margin=0.5로 설정한 것과 결과가 거의 똑같았다.둘 다 작아서 그런 건가?)
Original Softmax(BottleNeck structure)
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 93.90 | 84.71 | Eval | ToyCar | 91.51 | 87.40 |
| ToyConveyor | 76.70 | 65.57 | ToyConveyor | 83.86 | 70.19 | ||
| Fan | 82.40 | 73.78 | Fan | 92.56 | 86.61 | ||
| Pump | 84.60 | 76.01 | Pump | 89.64 | 80.15 | ||
| Slider | 97.61 | 88.18 | Slider | 90.31 | 77.48 | ||
| Valve | 94.75 | 89.23 | Valve | 98.14 | 94.333 | ||
| Mean | 88.33 | 79.58 | Mean | 91.00 | 82.69 | ||
| Harmonic Mean | 87.66 | 78.62 | Harmonic Mean | 90.80 | 81.95 |
CosFace
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 92.21 | 86.01 | Eval | ToyCar | 94.10 | 87.64 |
| ToyConveyor | 79.98 | 66.50 | ToyConveyor | 79.48 | 67.11 | ||
| Fan | 84.05 | 76.30 | Fan | 94.51 | 88.46 | ||
| Pump | 85.22 | 75.79 | Pump | 94.03 | 84.84 | ||
| Slider | 96.78 | 86.83 | Slider | 90.41 | 75.76 | ||
| Valve | 96.13 | 91.69 | Valve | 98.62 | 95.19 | ||
| Mean | 89.06 | 80.52 | Mean | 91.86 | 83.17 | ||
| Harmonic Mean | 88.61 | 79.59 | Harmonic Mean | 91.43 | 82.07 |
ArcFace(위 Integrated-Model와 같은 값)
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 94.84 | 88.82 | Eval | ToyCar | 96.16 | 91.69 |
| ToyConveyor | 80.09 | 66.91 | ToyConveyor | 83.81 | 69.59 | ||
| Fan | 84.92 | 77.22 | Fan | 96.57 | 90.54 | ||
| Pump | 89.68 | 80.88 | Pump | 93.72 | 85.10 | ||
| Slider | 97.92 | 89.34 | Slider | 91.50 | 79.35 | ||
| Valve | 97.01 | 94.49 | Valve | 99.10 | 97.47 | ||
| Mean | 90.75 | 82.85 | Mean | 93.48 | 85.62 | ||
| Harmonic Mean | 90.26 | 81.78 | Harmonic Mean | 93.20 | 84.58 |
ArcFace Loss를 사용한 모델이 가장 좋은 결과를 보여주고 있다.
추가로, Focal Loss를 사용한 결과는 아래와 같은데, ArcFace Loss보다 성능이 좋지 않았다.
Focal Loss($\alpha =1, \gamma =1$)
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | Mean | 87.96 | 79.61 | Eval | Mean | 92.06 | 82.76 |
| Harmonic Mean | 87.36 | 78.87 | Harmonic Mean | 91.82 | 81.92 |
Transfer Learning
DCASE2021, DCASE2022 Task2는 이 task와 매우 동일하지만 “domain shift” 조건이 추가된 좀 더 어려운 task이다. 2021년에는 제대로 해낸 팀이 없었다
비슷한 Task여서 상위 팀들의 Technical Report를 참고하던 중, [3]에서 다음과 같은 내용을 보았다.
Note that it is very easy to directly train a classifier to distinguish between different IDs of the same machine type using a neural network, which means that the model is often overfitted. To address this issue, we propose a robust anomalous sound detection framework. First, we use all machine types to train a classifier that can simultaneously distinguish different machine types with different IDs. Next, we fine-tune the model parameters to train a dedicated classifier for each machine type.
해당 부분을 참고해서, Integrated-Model로 학습한 모델의 파라미터를 가져오고, 6개 각각의 machine에 대해 Final Classifier layer만 fine-tuning한 모델을 따로 써보았다. Pre-train을 전체 Development Dataset으로 하고, Fine-tuning을 각 machine dataset으로 한 일종의 transfer learning을 한 거다. 결과는…
| Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) | Dataset | Machine Type | AUC(%) | pAUC(%)(p=0.1) |
|---|---|---|---|---|---|---|---|
| Dev | ToyCar | 95.57 | 89.20 | Eval | ToyCar | 93.50 | 89.33 |
| ToyConveyor | 76.11 | 66.90 | ToyConveyor | 85.95 | 71.37 | ||
| Fan | 87.65 | 81.78 | Fan | 94.87 | 91.58 | ||
| Pump | 91.96 | 82.77 | Pump | 94.71 | 86.72 | ||
| Slider | 98.54 | 93.12 | Slider | 96.51 | 87.68 | ||
| Valve | 99.50 | 98.35 | Valve | 98.66 | 96.67 | ||
| Mean | 91.55 | 85.35 | Mean | 94.03 | 87.22 | ||
| Harmonic Mean | 90.79 | 84.06 | Harmonic Mean | 93.86 | 86.45 |
아주 조금의 성능 개선! 사실 처음에 integrated-model을 학습할 때 실수로 valve의 AUC, pAUC 합이 최대가 될 때 갱신하도록 설정했었는데, 이 때 valve의 AUC가 매우매우 높게 나와서 (99.9x) 뭔가 이런 식으로 feature extraction을 generalize 하는 방법이 괜찮을 거 같다는 생각을 하긴 했었다. 아무튼 굳
T-SNE in Feature Dimension
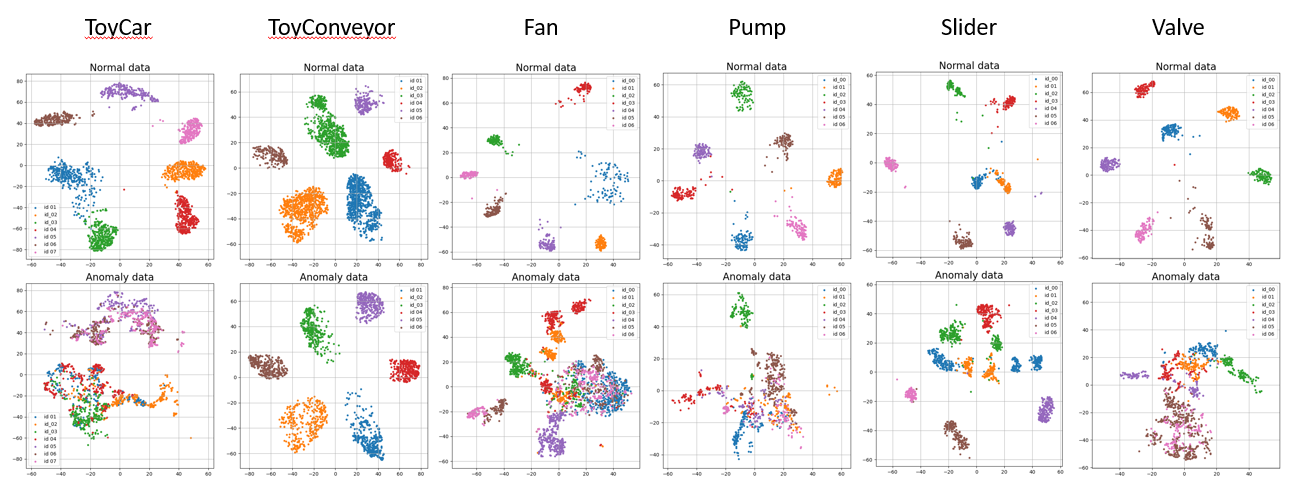 위 T-SNE 그림에서 알 수 있듯이, ToyConveyor의 경우 Normal data도 구분을 잘하고, Anomaly Data도 구분을 잘 하는 상황이 벌어진다. 직접 Sound data를 들어보면 ToyConveyor는 id마다 특징이 너무 달라서 비정상 데이터도 구분을 잘하고 있다. 이 점을 통해서, Classification-based method로 ToyConveyor를 평가할 때 limit가 있을 거라 생각이 된다… ㅠ
위 T-SNE 그림에서 알 수 있듯이, ToyConveyor의 경우 Normal data도 구분을 잘하고, Anomaly Data도 구분을 잘 하는 상황이 벌어진다. 직접 Sound data를 들어보면 ToyConveyor는 id마다 특징이 너무 달라서 비정상 데이터도 구분을 잘하고 있다. 이 점을 통해서, Classification-based method로 ToyConveyor를 평가할 때 limit가 있을 거라 생각이 된다… ㅠ
Anomaly-Score Calculation
현재, 모델 학습 및 평가 시 anomaly score를 1 - (해당 machine id의 softmax probability)로 설정하였다. 이는 Basic Idea에서 설명한, 굉장히 직관적인 anomaly score 계산 법이고, 다른 논문들에서 다양한 식을 활용해 이를 구하고 있다.
- 1. Normal Data의 Feature centroid와의 cosine similiarity. 다만, feature가 2048 dim.에 있어서 뭔가 매우 안 좋은 결과가 나올 것 같다. (Curse of Dimensionality)
- 2. GMM (Gaussian Mixture Model)
- 3. LOF (Local Outlier Factor)
해보면 좋을 것으로 예상되었으나, scikit-learn에서 제공하는 GMM, LOF를 사용하니까 CPU를 너무 많이 잡아먹고 있다. GPU 상에서 돌아가는 게 아니라서 그런 것 같은데, GPU에서 되도록 구현해둔 다른 오픈소스를 활용하면 좋을 것 같다.
Reference
[1] Deng, J., Guo, J., Xue, N., & Zafeiriou, S. (2019). Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4690-4699).
[2] Wu, J., Yang, F., & Hu, W. (2023). Unsupervised anomalous sound detection for industrial monitoring based on ArcFace classifier and gaussian mixture model. Applied Acoustics, 203, 109188.
[3] Zeng, Y., Liu, H., Xu, L., Zhou, Y., & Gan, L. (2022). Robust anomaly sound detection framework for machine condition monitoring. DCASE2022 Challenge, Tech. Rep.
댓글남기기