[CS231n] Lecture 8&9
Lecture 8 - Deep Learning Software
CPU vs GPU
일반적으로 CPU의 Core 수는 4 또는 8인데, GPU의 Core 수는 이것보다 훨씬 많다. 강의 자료에는 NVIDIA GTX 1070 기준으로 CUDA Core 개수가 1920, NVIDIA V100 Tensor Core는 CUDA Core 개수가 무려 5120개. 이처럼 GPU는 CPU에 비해 core가 훨씬 많지만, 각각의 core는 CPU에 비해 훨씬 느리다. 따라서 matrix multiplication과 같은 parallel processing이 가능한 task에 적합하다.
여기서 말하는 CUDA(Compute Unified Device Architecture)는 NVIDIA에만 있는 기술로, GPU에서 수행하는 parallel processing 알고리즘을 C-like 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술이다.
Pytorch
강의 자료에는 Caffe2, TensorFlow에 대한 기본적인 예시도 알려주지만 pytorch만 살펴보았다. Pytorch에는 크게 Tensor, Variable, Module 3가지 level의 abstraction이 있다. Tensor는 numpy array와 상응하고(GPU에서 돌아가는게 차이), Variable은 data와 gradient를 저장하는 말 그대로 변수이고, Module은 NN layer로 weight를 저장하는 것이다.
해당 강의에서는 pytorch의 autograd에 있던 Variable API를 쓰는데, 이는 이제 사라졌고 autograd는 tensor에 이제 requires_grad를 True로 세팅하면 자동적으로 적용된다. 아무튼 아래는 강의에서 제공해준 Toyexample인데, 사실 Lecture 3&4 Review에서 작성한 것과 거의 동일하다.
# CS231n 2017 Lecture 8 PyTorch example codes
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
# Define New Modules
class TwoLayerNet(nn.Module):
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.linear1 = nn.Linear(D_in, H)
self.linear2 = nn.Linear(H, D_out)
def forward(self, x):
x = self.linear1(x)
x = nn.ReLU(x)
x = self.linear2(x)
return x
# Or use pretrained Models
resnet101 = torchvision.models.resnet101(pretrained=True)
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
loader = DataLoader(TensorDataset(x, y), batch_size=8) # dataloader
model = TwoLayerNet(D_in, H, D_out)
criterion = nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
for epoch in range(10):
for x_batch, y_batch in loader:
optimizer.zero_grad() # Reset previous gradients (if not, then result will stack)
y_pred = model(x_batch)
loss = criterion(y_pred, y_batch)
loss.backward()
optimizer.step() # Parameter Update
Lecture 9 - CNN Architectures
Lecture 5에서 CNN의 예시로 LeNet-5를 다루었었다. [5x5 Conv]->[2x2 AvgPool]->[5x5 Conv(*)]->[2x2 AvgPool]->[FC]->[FC]로 구성되는 파라미터 6만개 짜리, 1998년에 제안된 네트워크였다.
AlexNet
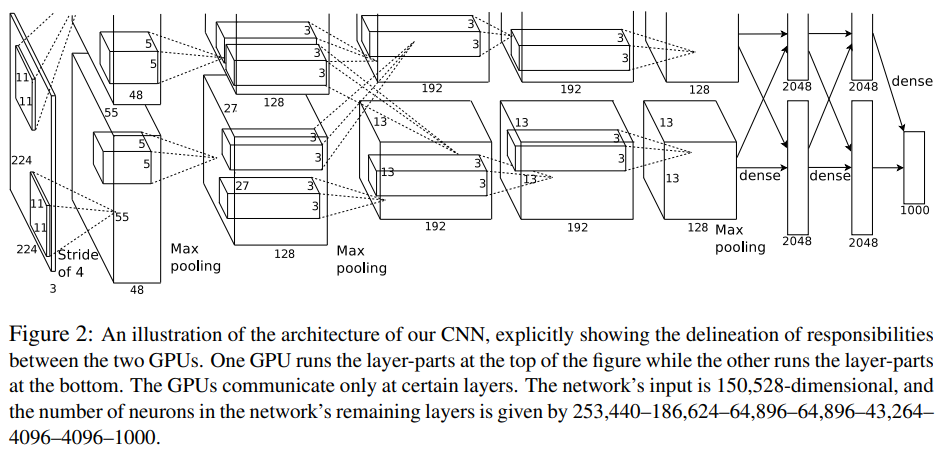

ILSVRC에서 처음으로 CNN-based model로 우승을 차지했던 2012년 AlexNet이다. 227x227x3 image를 input으로 하여 [227x227x3]->[55x55x96]->[27x27x96]->[27x27x256]->[13x13x256]->[13x13x384]->[13x13x384]->[13x13x256]->[6x6x256]->[4096]->[4096]->[1000]가 된다. (Conv->MaxPool->Norm)x2 + (Conv)x3 + MaxPool + FCx3, 총 8 layer로 구성되어있다.
VGGNet

VGGNet은 AlexNet보다 층을 더 쌓아서 19 layer로 구성되어 있다. AlexNet은 filter size로 처음에 11x11와 5x5를 썼지만, VGGNet의 경우 filter size를 3x3만을 채택하면서 동시에 층을 더 깊게 쌓았다. 3x3 filter의 CNN layer 3개를 쌓는 것은 7x7 filter의 CNN layer 1개와 동일한 pixel 정보(동일한 receptive field)를 보는데, 더 깊으면서도 더 nonlinearity를 챙길 수 있게 되는 장점이 있다. 또한, 파라미터 개수도 3x3x3=27 < 1x7x7=49, 더 적은 장점이 있다. 각 층마다 디테일한 정보는 사진에 자세히 나와있다.
GoogLeNet
GoogLeNet부터는 단순히 CNN, Pooling, Norm, FC를 쌓아 올린 구조가 아니라 조금의 변형이 있다. 2014년 발표한 GoogLeNet에서는 computational efficiency를 위해 FC layer는 없고, Inception module이라는 것을 도입했다.
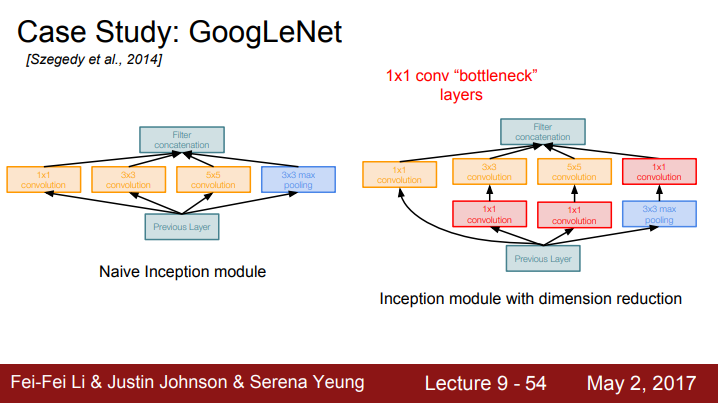
Inception Module의 기본 Idea는 여러 개의 filter size (1x1, 3x3, 5x5)를 가지는 CNN layer를 parallel로 배치하여 (3x3 Pooling layer도) output은 이 모두를 concatenate하는 것이다. 그러나 사진의 왼쪽처럼 Naive한 방법의 inception module은 computational cost가 매우 높다. 그래서 오른쪽 처럼 1x1 conv bottleneck layer를 추가하여 depth를 낮춘 뒤에 위의 idea를 적용하는 것이다.
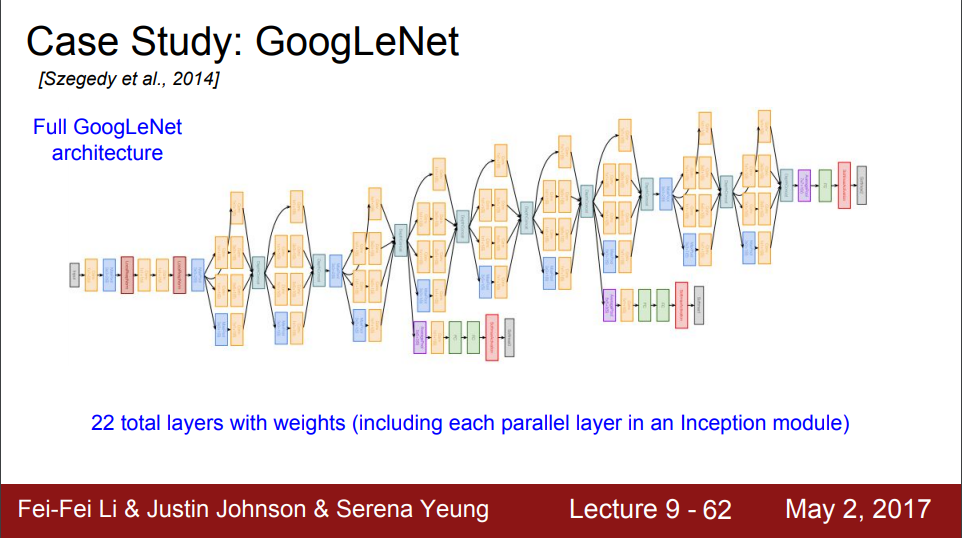
전체적인 큰 틀은 3단계로, 1단계는 Stem Network: Conv-Pool-(Conv)x2-Pool, 2단계는 Inception Module 쌓아놓은 거, 3단계는 마지막 Classifier이다. 그리고 마지막 classifier와 거의 유사한 층이 inception module stack해둔 것 중간중간에 위치해있는데, 이는 lower layer에서 gradient를 주입하기 위한 보조장치 느낌이라고 한다.
ResNet
이렇게 층을 깊게깊게 쌓는게 당시 유행이 되었지만, 층을 무조건 깊게 쌓는다고 좋은 결과가 나오는 것이 아니다. 강의에서는 deeper model은 optimize하기 힘들다고 되어있는데, 그 이유는 vanishing gradient problem이 되겠다. backprop시 gradient를 구하는 과정에 있어서 early layer의 parameter에 대해서는 거의 gradient가 0이 되어 결국 optimize하기 힘든 것.
이 때, 2015년 ResNet이라는 획기적인 Idea를 제시한 네트워크가 제시되었다. ResNet 논문의 인용 수는 볼 때 마다 놀랍다. 2023년 7월 기준 인용 수 무려 171950회.
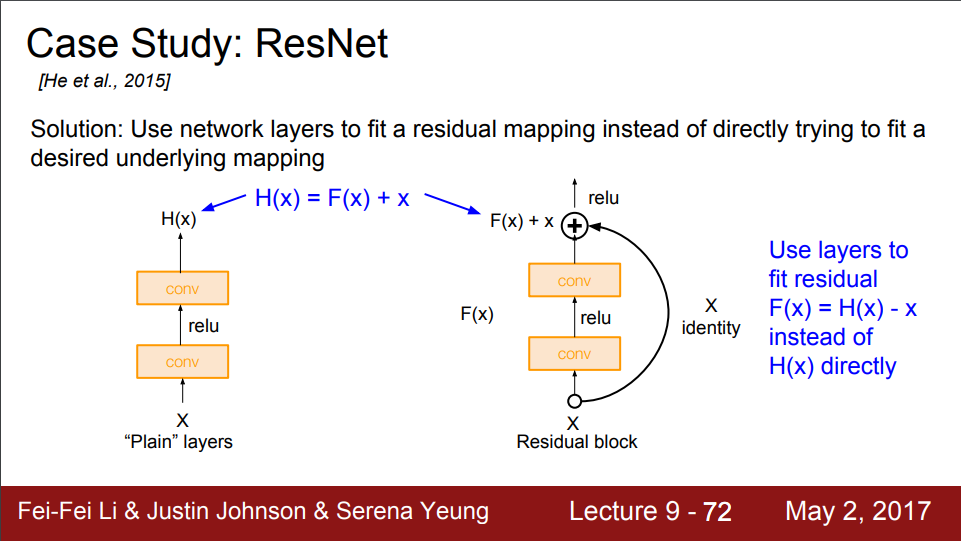
Main Idea는 Skip connection이다. 그림과 같은 방식의 identity를 더하는 방식은 해당 layer가 별 쓸모 없으면 weight가 0에 가까워 지면서 regularization은 그냥 이것을 skip할 것이기 model의 performance를 해치지 않음과 동시에 해당 layer가 유용할 경우 weight가 기존처럼 update 되면서 model의 performance를 증가시킨다. 이 때, input과 output의 dimension이 맞지 않는 경우에는 input을 Conv2d layer에 추가로 넣어주어 downsampling을 통해 dimension을 맞춰 준다.
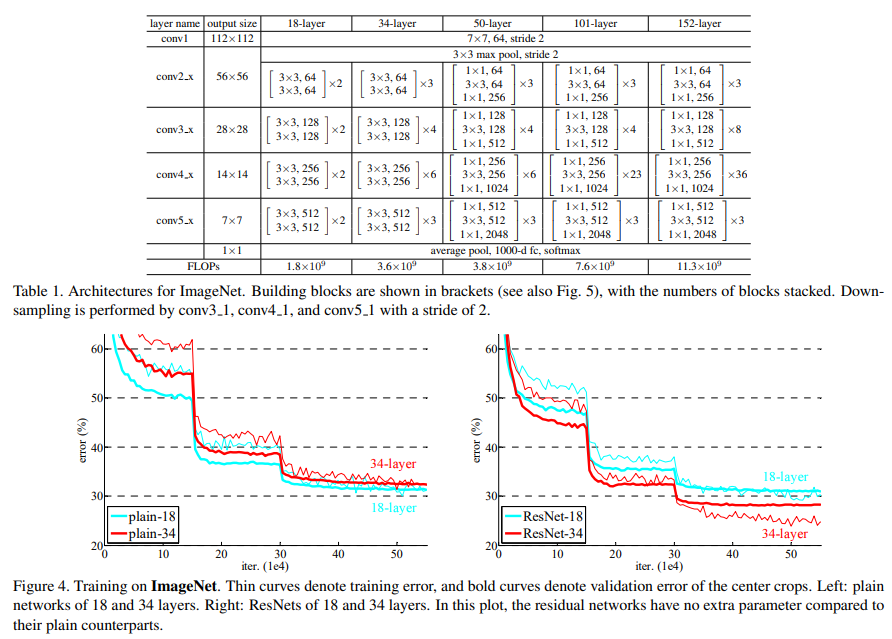
모델의 구조는 그림과 같다. 이 때, ResNet-50+ 구조에서는 3x3Conv->BN->ReLU->3x3Conv->BN->ResidualConnection->ReLU의 BasicBlock이 아닌 BottleNeck 구조를 사용하는데, GoogLeNet처럼 1x1 Conv를 추가로 사용하는 것이다. 자세하게는, 1x1Conv->BN->ReLU->3x3Conv->BN->ReLU->1x1Conv->BN->ResidualConnection->ReLU. pytorch torchvision의 resnet source code에서 BasicBlock과 Bottleneck class의 코드를 보면 이렇게 구현되어 있다. [Torchvision ResNet]
Improving ResNet
WideResNet은 기존의 ResNet basic block에서 F개의 filter가 아닌 Fxk개의 filter를 사용해서 각 layer의 width는 증가시키고, depth는 감소시킴으로써 computationall efficiency를 챙기고(parallelize) 동시에 성능도 개선한 모델이다. 실제로 50-layer WideResNet이 기존의 152-layer ResNet보다 성능이 좋다고 한다.
ResNeXt는 각 layer의 width는 증가시키는 것은 동일한데, 앞선 WideResNet과 다르게 F개의 filter가 아닌 F/32개의 filter를 가지는 path를 여러 개 구성한 뒤 이후에 concatenate하는 방식을 취했다. 마찬가지로 parallel multiway를 구성했기에 computational efficiency를 챙겼다.
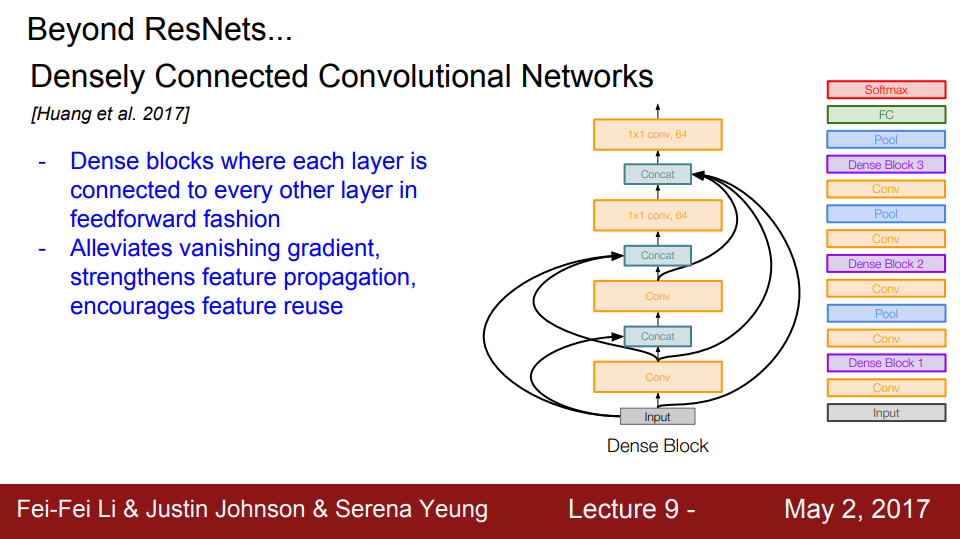
DenseNet은 그림에 나와있는 DenseBlock 구조를 이용하는데, 앞선 layer의 값을 이후 concat하는데 모두 사용하는 구조이다. 같은 파라미터나 연산량 (#Flops)을 기준으로 ResNet 대비 좋은 성능을 보였다.
참고로 2023년 2월 13일에 나온 Symbolic Discovery of Optimization Algorithms이라는 논문이 2023년 7월 3일 기준 ImageNet SOTA를 기록하고 있는데, Lion(Evolved sign momentum)이라는 새로운 optimizer를 통해 Vition Transformer에서 성능을 개선하였다.
Reference
강의 및 그림 출처 1 (http://cs231n.stanford.edu)
[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
[2] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
ImageNet SOTA (https://paperswithcode.com/sota/image-classification-on-imagenet)
댓글남기기