[CS231n] Lecture 6&7
이제 본격적으로 딥러닝 모델 학습에 대한 자세한 내용들을 다루고 있다.
Lecture 6 - Training Neural Networks I
Activation Function

과거에 많이 썼던 sigmoid function ($\sigma’=\sigma(1-\sigma)$)을 살펴보면, 다음과 같은 단점들이 있다.
- Vanishing gradient - Saturated될 경우 gradient가 0에 가깝다.
- Not zero-centered - 그림에 잘 설명 되어 있다.

input이 항상 양수라면, (local) gradient w.r.t. w가 x이므로 항상 양수, 즉 Upstream gradient의 부호를 무조건 다르게 된다. 그러면 그림처럼 weight update가 항상 양수이거나(1사분면), 항상 음수인(3사분면) 방향으로 진행된다. 만약 파란색 way가 최적의 길이라면, 우린 빨간색 처럼 둘다 줄였다가 둘다 키웠다가를 반복하는 헛고생을 하게 된다. 이를 막으려면? zero-centered data, 양수 음수가 골고루 있는 데이터가 좋다. 그러나 sigmoid는 그렇지 않다는 점. - Computaional Cost - exponential function은 polynomial에 비해 expensive하다.
그리고 또 많이 썼던 tanh function ($f’=1-f^2$)은 위의 3가지 단점 중 2번은 해결이 되지만, 마찬가지로 1번과 3번 문제를 가지고 있다.
ReLU
딥러닝의 획기적인 발전을 이끌었던 ReLU. ramp 함수, max 함수 뭐 이름이 많다만 나도 이제 ReLU가 가장 익숙하다
($f’(x)=sgn(x)= \begin{cases} 1& \text{ if } x>0, \ 0& \text{ if } x<0 \end{cases}$)
- Vanishing gradient - (+) region에서는 해결 되었으나, (-) region에서는 여전히 grad.가 0이다.
- Not zero-centered - 해결 안 됨.
- Computational Cost - 매우 computational efficient 하다. 6배 빠르다 그랬나…
- “Dead ReLU” - learning rate가 높거나, initialization이 나빠서 output이 전부 0인, 아무것도 activate 되지 않는 경우가 있다. data manifold가 ReLU가 적용하는 범위를 아예 벗어났다고 보면 된다. 그래서 보통 ReLU를 initialize 할 때 무조건 activate 하기 위해 작은, 양의 bias term을 의도적으로 넣기도 한다.
그래서 여전히 해결되지 않은 일부 1번 문제 및 2번 문제를 위해 Leaky ReLU, PReLU, ELU, SELU, MAXOUT, GELU 등 여러 변형 작들이 있다. 그리고 컴퓨터에 최적으로 하는 ReLU6 등 뭐 이것저것 있는데, 자세한 사항은 역시 또 pytorch 공식 문서를 참고하는게 늘 도움이 된다.
Pytorch Activation
ReLU가 무적은 아니다. Physical-informed Nerual Network(PINN)을 학습할 때 2nd order derivative가 system of ODE/PDE에 있는데 ReLU 썼다가 큰일 났던 경험이 있다.(ReLU의 2차 미분은 always 0)
Preprocessing
처음에 data가 있을 때, zero-mean & normalize 해주는 게 학습에 좋다. 앞서 말한 zero-centered data가 좋은 이유와 일맥상통한데, 추가적으로는 loss가 weight의 변화에 less sensitive해서 (그렇지 않다면 weight가 조금만 변해도 output이 미쳐 날뛴다) optimize하기 조금 더 쉬운 장점이 있다. torchvision을 사용한다면 주로 보이는 코드인,
transforms = torch.nn.Sequential(
transforms.CenterCrop(10), # Data Augmentation. Lecture 7 참고.
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
)
여기서 mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)로 주는 transforms.Normalize가 위에서 말한 걸 하고 있다. torchvision은 image data 많아서 mean, std 숫자가 이걸로 거진 fix된 느낌인데, torchaudio도 제공해줘 ㅠ 물론 주어진 dataset에서의 channel마다의 mean, std를 직접 구해서 활용해도 된다.
그리고 PCA나 whitening 같은 조금은 더 complex한 preprocessing technique을 써도 된다.
Weight Initialization
weight parameter의 초기값을 어떻게 설정하는지도 모델의 성능에 꽤 영향을 준다. Gaussian Distribution으로부터 random value를 받아서 initialization을 할 경우, std가 작다면 모든 activation이 0이 되어서 gradient가 모두 0이 될 것이고, std가 커도 tanh를 거친다면 output이 매우 커서 -1 or 1로 saturated, gradient가 0이 된다.
그래서 적당한 std를 선택하는데, $std=1/\sqrt(D_{in})$ (CNN의 경우 (filter size)^2 * channel_in이 되겠다)로 시작하는 것을 Xavier initialization이라 한다.
그러나 tanh가 아닌 ReLU를 쓸 때, Xavier initialization 또한 vanishing gradient 문제가 발생하는데, $std=1/\sqrt(D_{in}/2)$ 를 쓴다 던지 뭐 다양한 attempt가 있다.
Batch Normalization (BN)
위에서 Normalization이 중요하다고 말해주었다. 즉, “layer의 output(다음 layer의 input이기도 하니 input이라 해도 되겠다)이 unit Gaussian distribution을 따르면 좋다”이다. 그럼 그냥 강제로 그렇게 되도록 하면 되는거 아닐까?
Batch Normalization은 기본적으로 어떤 layer에서 Batch 단위로 들어온 data의 activation 결과 값들이 input으로 들어올 때, Batch 단위로 mean과 variance을 이용하여 Normalization을 하는 것이다. (조금 더 정확히는 unit gaussian을 따르게 된다면 saturation이 전혀 이루어 지지 않기 때문에, scaling & shifting을 추가적으로 거쳐 saturation도 일부 일어나는 유연성을 얻게 된다.) 이렇게 되면 앞서 말했던 weight initialization의 중요도가 상대적으로 떨어지게 된다. 그리고 mean과 std.는 상수이기에 미분도 가능해서 Backpropagation에 문제도 없다.

주로 FC layer와 Activation 사이에 BN layer를 추가해주어서 앞서 말한 문제들(vanishing gradient 라던지, inefficient weight update 라던지)이 일어나지 않도록 해준다.
Hyperparameter Optimization
네트워크 구조, learning rate, optimizer, scheduler, regularization 등등을 최적화 하는 건데, 이건 아직 정답이 없잖아 이론 상 random search로 learning rate를 찾는게 조금 더 좋다고 말하고 있다. optimizer와 같은 내용은 Lecture 7에 내용이 나온다.
Finally
끝으로 Training과 Validation 시의 accuracy를 체크하면서 overfitting이 일어나고 있는지, 혹은 전혀 차이가 없으면 모델 capacity를 늘려보는 시도를 해보는 것도 방법이 된다. weight update 사이즈가 weight 크기에 비해 너무 크거나 작으면 또 안 좋다. 뭐 이런 얘기를 간단히 하고 있다.
Lecture 7 - Training Neural Networks II
Optimization
Lecture 3에서 parameter optimization technique으로 gradient descent (GD), 그리고 조금 더 fancy한 stocastic gradient descent (SGD)를 배웠다. 여전히 SGD도 단점이 있는데, 쉽게 생각할 수 있는 건 local minima point, 혹은 saddle point의 경우 parameter가 stuck 되는걸 생각할 수 있다. 그래서 더욱 더 fancy한 optimizer에 대해 설명하고 있다.
Opitimizer에 대해 공부 할 때 다른 분 블로그에서 우연히 본 사진이 있는데, 그거 진짜 맨날 보게 된다. 나도 빠져들었다 그래서 나도 사진으로 대체…

Pytorch도 당연히 Optimizer를 제공해주고 있다. 구체적인 식보다는 이 optimizer는 이렇게 행동하는구나 정도만 이해하고, parameter로 뭐를 받고 있는지 체크하는 정도면 충분하지 않을까 생각한다. Pytorch Optimizer
2nd Order Optimization.
Lecture에서 2nd order Optimization (Newton’s Method) 또한 설명해 주고 있는데, 일단 딥러닝에서는 Hessian matrix의 computational cost가 크니까 쓸 일이 없어서 자세히 듣지는 않았다. MAS480 SciML 특강에서 Hessian matrix 대신 근사하는 Gauss-Newton’s Method (kinda 1.5th order optim.), 그리고 1971년 Fletcher가 발표한 “A modified Marquadt subroutine for non-linear LSQ” 에서의 Levenberg-Marquadt algorithm도 배웠었는데.. 빨리빨리의 민족은 이딴 거 쓸 리가
Scheduler
Learning rate scheduler에 대한 정리는 다른 분 블로그에 더 정리가 잘 되어 있는 거 같아서 넘어가겠다. 사실 몇 번 모델을 학습해보면, scheduler가 모델의 성능에 엄청난 개선을 주지는 않아서.. 일단 scheduler 없이 학습해보고 성능을 소위 쥐어 짜내고 싶을 때 쓰고 있다.
Model Ensemble
- Train multiple independent models
- Average their results at test time 일반적으로 이렇게 하면 performance가 조금 더 증가한다고 얘기하고 있다. hyperparameter, model size를 다르게 해가면서 average 해도 된다.
Regularization
Lecture 3에서 우리는 regularization technique으로 L1 regularization, L2 regularization을 살펴보았는데, 이제 실제로 주로 쓰이는 더 다양한, fancy한 technique에 대해 설명하고 있다.
Dropout
Dropout은 forward pass시 Layer의 일부 neuron을 0으로 만드는 방법을 얘기한다.
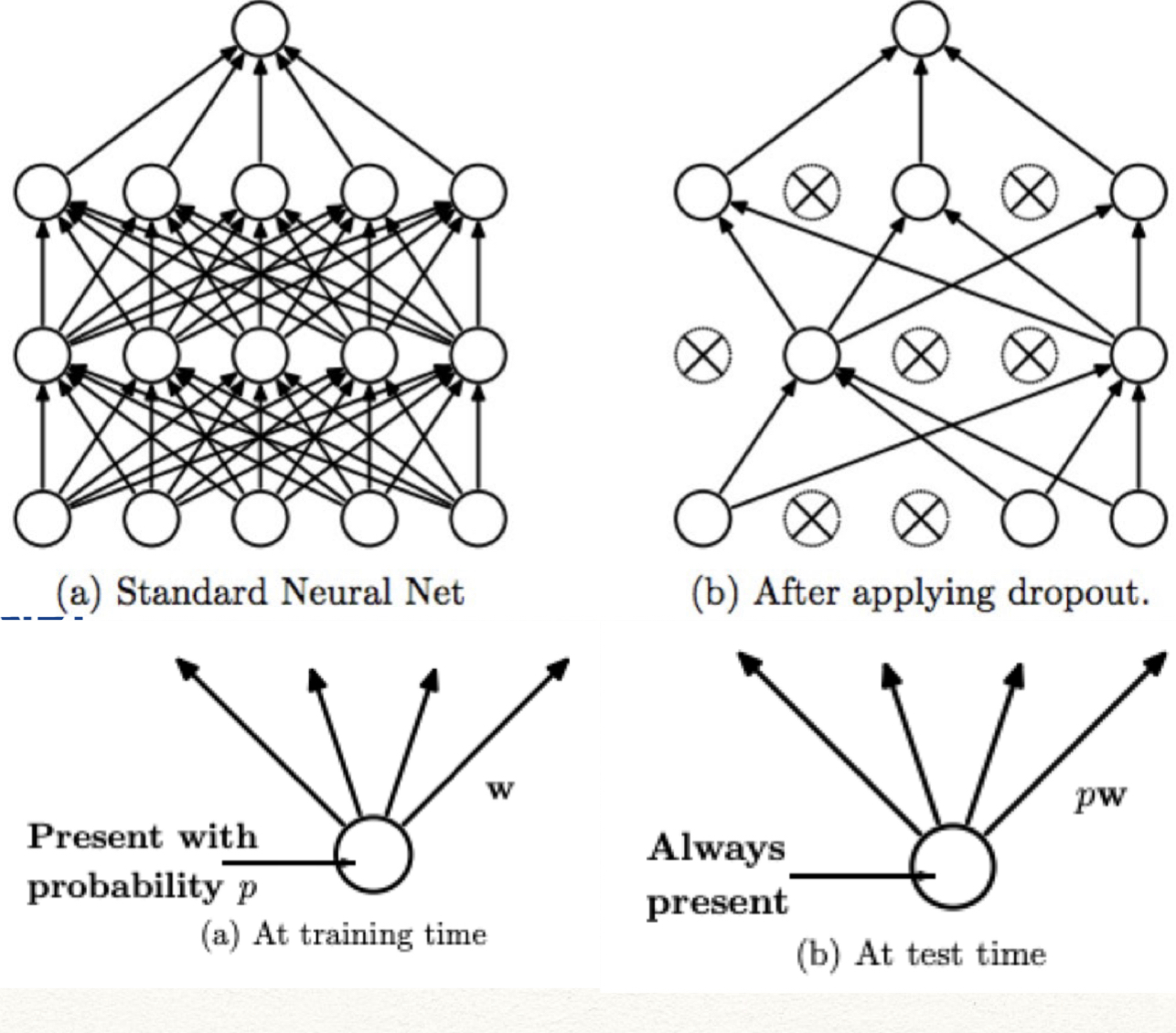
조금 더 정확히는, training 시에는 각 hidden layer마다 neuron들의 random portion (ex:p=0.5)를 zero-out 하고, testing 시에는 nueron의 activation result를 p 배 해준다. (이는 p의 확률로 존재하는 걸 보정하는 느낌으로 생각하면 될 것 같다) 혹은, “Inverted dropout”이라고 이름 붙여뒀던데, training 할 때 부터 weight를 p로 나누어주는 방법도 있다. (이는 p의 확률로 존재하는걸 보상해주는 느낌으로 생각하면 될 것 같다) Pytorch Dropout
Dropout이 왜 좋은지 생각해보면, 애초에 layer의 neuron 수를 줄이는 것과는 다르게 redundant representation을 가지게 되므로 특징 간의 co-adaption(매우 유사한 특징을 뽑는 문제)을 방지할 수 있게 된다. 혹은, 이게 randomly zero-out을 하기 때문에 많은 모델의 ensemble로도 생각할 수 있기에 좋은 성능이 나온다고 볼 수도 있다.
Data Augmentation
어떤 Data 1개가 있을 때, 그 데이터에 특정 operation을 가해서 공짜로 data 양을 늘리는 것을 말한다. Data가 많을 수록 모델이 generalized 해지는데 도움이 되고, 학습도 잘 되고, 안 좋은 게 없기 때문이다. translation, rotation, stretching, crop, scaling, flip, darkening, add noise, distortion 등 매우 창의적인 방법이 많다. 그럴 땐? pytorch 공식 문서로. Torchvision Transform
주의할 점으로는 transform들 중 몇 몇은 조심해야 된다. 가령 Optical Character Recognition(OCR) task에서 6과 9의 image를 rotating 하는 경우라던가, p와 q의 image를 flipping 하는 경우라던가, 아니면 face recognition task에서 darkening은 인종 구분이 힘들어진다던가…
Transfer Learning
충분한 데이터가 없는 경우 overfitting이 일어날 가능성이 매우매우 크다. 그래서 매우 큰, Imagenet과 같은 dataset에서 학습을 먼저 한 뒤, 우리의 작은 dataset에서 추가적으로 학습을 한다. 이 때, Imagenet에서 학습한 model에서 final classifier를 제외한 나머지 layer의 parameter는 freeze한 상태로 우리의 작은 dataset에서 학습하여 마지막 layer의 parameter만 학습해 update한다. 혹은 dataset이 그렇게 작지는 않다거나, 우리의 dataset이 앞서 학습한 Imagenet과 같은 dataset과는 상당수 다른 부분이 있다면, Final classifier를 포함한 뒤의 일부 layer를 더 추가해서 그 부분만 학습하게도 할 수 있다. 보통 이런 과정을 pretrain -> fine tuning 이렇게 부른다.
매우 큰, 일반적인 dataset에서 pretrain 과정을 거치면 일반적으로 매우 잘 작동하기에 우리의 데이터셋에서 특정 task를 할 때 좋은 initialization이 되어 성능이 좋아지게 되는 것이다.
torchvision에서도 pytorch torch.utils.model_zoo를 이용하여 pre-trained model을 제공해 주고 있다. pretrained=True만 pass해주면 된다. Torchvision Models
Reference
강의 및 그림 출처 1 (http://cs231n.stanford.edu)
[그림 출처 2] 2022 Fall EE488(B) DL for CV Lecture Note (by Prof. Jung)
그림 출처 3 (https://www.slideshare.net/yongho/ss-79607172)
자료 출처 1 (https://gaussian37.github.io/dl-pytorch-lr_scheduler/)
댓글남기기