[CS231n] Lecture 1&2
Stanford University에서 Youtube에 게시한, CS231n Convolutional Neural Networks for Visual Recognition 수업 자료 개인 정리 Version.
강의가 2017년에 있었고, 나는 22F KAIST EE에서 정준선 교수님의 EE488 Deep Learning For Computer Vision 수업에서 supervised-learning 관련 내용들을 학습했기에 cs231n 비디오에서 Unsupervised learning 관련 내용들을 중점으로 볼 예정이다.
우연히 들어오셨다면, 정말 간단한 정리를 원하시는 게 아니라면 다른 블로그의 정리 글을 보시는 걸 추천드립니다.
간간이 앞부분에서는 영상에서는 없지만 2017년 이후 발표된 관련 논문들에 대한 내용도 정리할 예정.
Lecture 1 - Introduction to CNN for Visual Recognition
Intro. 별 내용은 없고, Computer vision의 역사에 대해 짧게 소개해준다. 1966년 MIT의 “THE SUMMER VISION PROJECT”에서 시작된 Computer Vision 분야의 발전 과정. Object Detection, Image segmentation, Image classification, Action recognition, Image captioning 등 여러 Task들과, LeNet, AlexNet, GoogleNet, VGGNet, ResNet 등 model architecture의 발전 과정을 알려줬네요 :)
Lecture 2 - Image Classification
Image Classification 설명
Computer Vision의 Core task인 Image Classification은, 말 그대로 사진을 주고 이 사진이 무슨 사진인지 맞추는 task이다. 이 Task가 컴퓨터에게는 매우 어려운데, 그 이유는 Semantic Gap(컴퓨터는 이미지를 0,1로 이루어진 pixel tensor로 인식하니까), Viewpoint Variation(객체를 바라보는 방향에 따라 컴퓨터가 인지하는 pixel 값이 달라지니까), Illumination, Deformation, Occlusion, Background Clutter, Intraclass variation 등 여러 이유가 있다.

가장 기초적인 생각으로는 물체의 edge를 본다던지, corner를 본다던지 등등을 생각할 수 있겠다..
Data-Driven Approach
- 이미지와 라벨로 구성된 Dataset이 있으면
- Machine Learning(ML)로 Classifier를 학습하고
- 새로운 input image에 Classifier를 적용시켜 결과값을 보면 된다.
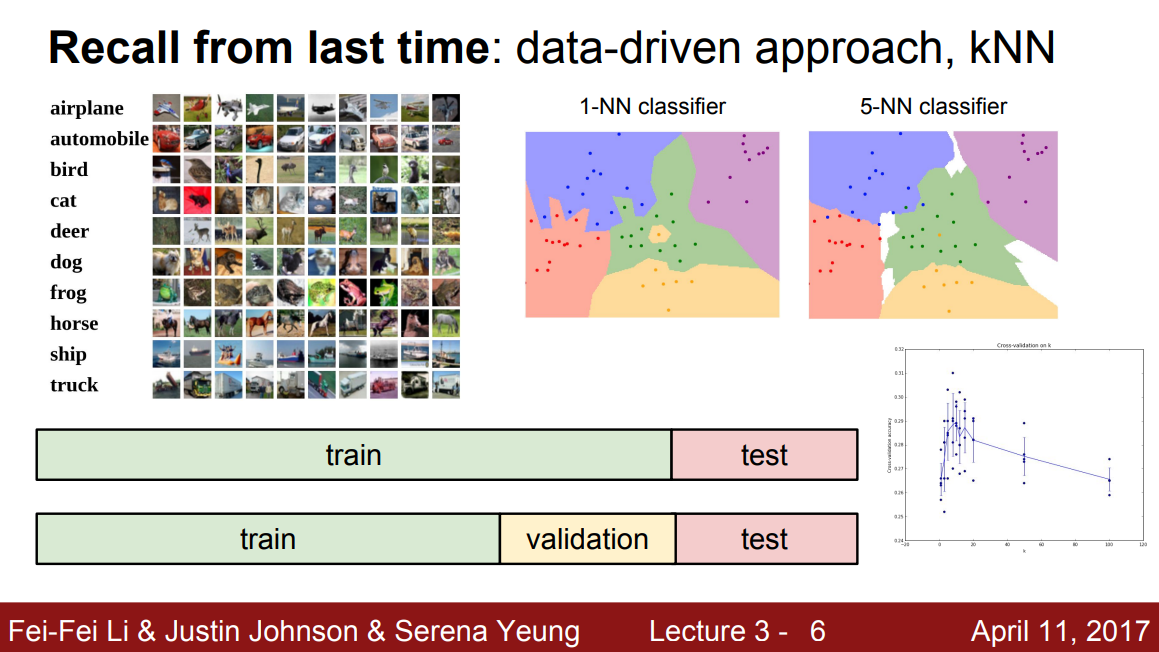
Nearest Neighbor(NN)
NN은 학습 시에 모든 데이터와 라벨을 기억해뒀다가, input이 들어오면 학습 때 사용했던 이미지들 중 가장 유사한 이미지의 라벨을 주면 되겠다. 너무 당연하다
이 때 이미지의 유사도를 수치화 하는, Distance Measure로 L1, L2 Distance를 아무거나 쓰면 되겠다.
근데 이게 안 좋은게, N개의 training dataset이 있다면 학습 시에는 시간 복잡도가 O(1), 예측 시에는 시간 복잡도가 O(N)이다. 즉, 학습은 뭐 오래 걸려도 미리 해두면 그만인데, 예측 시에 오래 걸리는 건 원하지 않기 때문에 별로다. 학습 시에 O(1)인 건 Data Size와 상관 없이 pointer를 잘 이용한다면 곧바로 되기 때문이다.
K-NN
NN에서 1개만 보는게 아니라 유사한 이미지 K개를 보고 결과를 결정하는 건데, Decision Boundary가 좀 더 smooth 해지는 장점이 있겠다. 그렇지만 여전히 Test time이 길고, pixel간 distance measure는 아무 정보를 제공해주지 않기 때문에 image classification에서는 이건 절대 안 쓴다고 뒤에서 얘기해주고 있다.
Hyperparameter
위에서 말한 K-NN를 이용한다면, K 값을 얼마를 쓸지, Distance Measure로는 어떤 걸 쓸지 이런 것들이 다 Hyperparmater에 해당한다. Hyperparameter tuning은 매우매우 problem-dependent 하므로 trial-and-error가 답이다.
Hyperparameter tuning에 대한 여러 논문들도 찾아볼 계획이다. 뭔가 알고 보면 어떤 Rule이 있지 않을까?
Training, Validation, and Test
그리고 어떤 모델을 구성할 때, Dataset을 Training dataset, validation dataset, 그리고 test dataset으로 나누어
- 학습은 training dataset에서,
- hyperparameter (parameter도) tuning은 validaion dataset에서 가장 잘 나오는 결과로
- 그리고 마지막 test dataset에서 최종 성능 체크.
이런 식으로 한다.
K Cross-Validation technique도 소개해주지만,
요즘 small dataset이 어딨냐
Linear Classifier
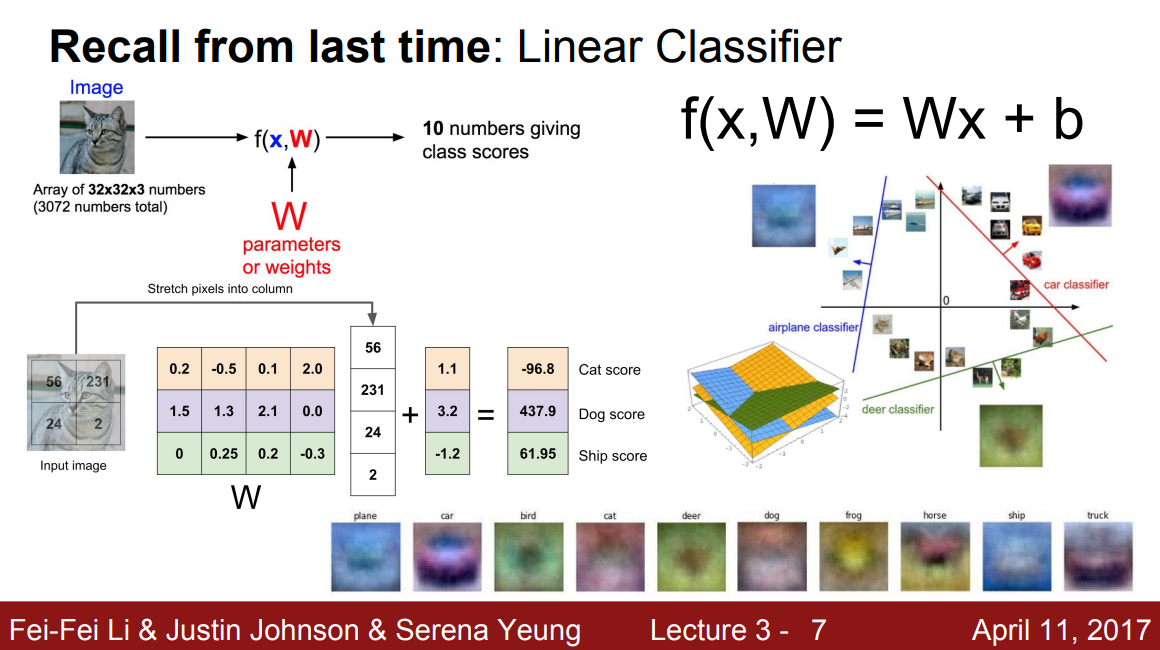
CIFAR10 Dataset의 input x, of size 3x32x32를 기준으로, weight(parameter) matrix W와 bias term b를 이용해 $f(x)=Wx+b$로 나타내는 Classifier. 식 그대로 Linear 하다.
Input shape인 torch.Size([3, 32, 32])를 flatten 해서 torch.Size([3072])로 나타낸다면, W의 shape은 torch.Size([10,3072]), b의 shape은 torch.Size([10])로 되어 output의 shape은 torch.Size([10])이 되는 구조이다.
output의 각 score 값(그림에서 -96.8, 437.9, 61.95)은 해당 class로 구분이 되는 정도를 뜻하며, 값이 높으면 해당 class일 확률이 더 크다고 해석하면 된다. (softmax도 곧 하겠지?)
weight matrix W의 각 row를, 각 class에 대한 정보를 나타내는 template이라 볼 수 있다. (첫 번째 row는, image pixel 정보와 곱해져서 첫 번째 class에 대한 정보를 제공해주기에… 그림에서 W matrix의 row 색깔이 특정 class를 나타내는 정보이다.)
그리고 $f(x)=Wx+b$ 는 high dimension(지금의 경우 3072 dim.)에서 class간 linear boundary를 제공하는 것이라 보면 된다.
Reference
강의 및 그림 출처 (http://cs231n.stanford.edu)
댓글남기기